xSTreamC language tutorial
Introduction
Mapping complex applications onto parallel architectures is difficult in spite of the large body of literature and programming tools available. Even more so for embedded distributed memory multiprocessor architectures that might not rely on the benefits and ease of use of cache coherency protocols based NUMA machines.
The xSTreamC language doesn’t cover the large space of parallel applications for every domain, but rather tries to leverage a streaming-oriented programming model that is a good fit for a significant portion of media and telecommunication based real-world applications. xSTreamC is based on C, augmenting it with constructs that make it a streaming language.
The genesis of the languages was strongly inspired by the work done by Saman Amarasinghe and his team at MIT for the streamIT language, while focusing on legacy and migration support.
xSTreamC Programming Model
At the basis of the xSTreamC programming model
is Synchronous and/or Dynamic Data Flow execution semantics. The language
provides an easy and intuitive way to assemble parallel programs by way of a
description of parallel tasks communicating via virtual queues of theoretically
unbounded size, or in practice bounded by the amount of local storage available
at any given node of a computing array of processors. In this sense the
language loosely resembles a theoretical distributed model of computation known
as a Kahn process
network
Exposing parallelism: language goals
Sequential Parallelism
The first way to express parallelism in the language is captured by sequential
parallelism: This is the possibility that, in a streaming application,
two consecutive stages of the same algorithm can be executed independently. It
is often found in the applications targeted by embedded multimedia and
telecommunication SoCs. This is one of the primary means of reaching
performance scaling with varying number of computing nodes, executing several
parts of the same algorithm by different units.
Data Parallelism
Another source of performance improvement comes from the data
parallelism which is present in many multimedia algorithms. This is
the possibility the algorithm (or at least some parts of it) can be executed
separately and independently on several sets of data. Think for example of
imaging algorithm working on image tiles. In many cases, we could perform the
same operation on several blocks at the same time, or at least independently.
Message Passing vs. Shared Memory
This is a rather big conundrum of parallel programming that has daunted computer scientists for decades; the xSTreamC language is by design closer to message passing although the deployment of it on shared memory systems is possible as well.
At the low-level support of the language an efficient ways of sending/receiving messages, or stream frames is required.
Assumptions
The choice of a message passing scheme is a crucial on. Here, several solutions are possible, of which most obvious are classic coherent memory, pure message passing, and FIFO or virtual queues. We chose the FIFO solution for several reasons:
- You don’t have to worry about overwriting a piece of memory used by another processor or pass around pointers to blocks containing messages.
- It is always coherent, because queues are managed atomically.
- It is easy to use with a blocking primitive semantics, which has the added benefit of automatic synchronization of tasks.
- Has the potential to scale better for large systems
Once this choice was made, we defined how we wanted our tasks to interact with each other. The last things to define was how tasks (or in the xSTreamC jargon ‘filters’) are linked together, and with the external world.
- A block of code with clear input and output streaming interfaces is called a filter. It’s characterized by different sections activated at different times in the filter lifetime, a steady-state section that is essentially a loop (the work section), and a number of ancillary states for initialization, parameter setting and completion of the stream of data associated to a frame.
- A set of few composable
primitives to arrange these filters into a more generic
task graph whose arcs represent data-flow.
A C based language
Any (
Additionally a short list of specific keywords is reserved
to xSTreamC. Thus, you cannot
use them as identifiers just like you cannot use “int” or “float” for that in
Reserved Keywords
The following list summarizes the keywords added to C, and reserved, in xSTreamC.
Global structure
xSTreamC offers ways to define a streaming data-flow graph or pipeline as a set of filters connected by queues.
An xSTream program can be split in two distinct parts:
General Purpose Part
It is a standard piece of C code; it is called this way because it should
run on a general purpose engine (GPE) anyway. The GPE can be
either an host controlling processor whose the parallel computing array is
attached to or just any one of the computing nodes; in reality there is no
limitation to the structure of this part of the code and as a matter of fact,
one could resort to even distribute this around onto multiple processor with a
conventional programming model such as a thread based one (or OpenMP or
similar).
Streaming Fabric
The other part is the part describing the streaming fabric,
namely the Processing Elements (PEs) and their network.
This will be the section that the xSTreamC compiler will
handle. Note that the execution of this part is not necessarily performed on
the PEs, as the compiler or runtime could take the
decision to run it, or part of it, on the GPE.
The GPE world
The xSTreamC run-time assumes the definition of a GPE or at least of an interface
to a layer that performs the associated operations.
Interfacing
The
interface with the streaming code is managed by the xSTreamC Runtime. What is left to the GPE
responsibility is the instantiation of the pipeline. At the programmer level
this is achieved simply by calling the “function” describing your pipeline. A
handler to the newly instantiate pipeline is returned by the runtime, and can
be used in subsequent calls to the
Indeed, the prototype of the function describing a pipeline (mypipe, in the example below) will be transformed by the compiler, so that the generated code returns a handler type. This handler is of type unsigned int when not using a template. In the case of the template, it will be defined by it, possibly using a custom type.
/* Example of pipeline instantiation */pipeline mypipe(int a, double b)
{(...)
}/* Standard case */int main()
{unsigned int handler;
handler = mypipe(0, M_PI);
}/* nSTream example */int main()
{ xst_pipe_handle handler;handler = mypipe(0, M_PI); /* instantiation */
/* Actual call of the pipeline */
}
Pipeline description
Following
is a description of the syntax used for describing the pipelines.
pipeline
A pipeline is a sequence of filters or other streaming language constructs (such as pipeline, or a split-join). The top level of your pipeline description must be a pipeline. You can, of course include other pipelines in nested levels.
The following description would be a simple sequence of two filters. In this simple description, gen_filter and av_filter are types of filters, while Generate and Average are the names of the filter instances; this is a subtle but important point, namely, filter names become amenable to types and can be used to instantiate multiple instances of a given filter.
![]() Keep in mind that
you could use several times the same filter (type), with different instances.
Then, everything inside would be replicated (even static variables) in order to
have two distinct filters.
Keep in mind that
you could use several times the same filter (type), with different instances.
Then, everything inside would be replicated (even static variables) in order to
have two distinct filters.
/* Simple pipeline example */pipeline mypipe()
{gen_filter Generate(params);
av_filter Average(other_params);
}

split - join
You
express more complex data-flow graphs, using split / join
sections. The following example shows a nested parallel section.
defaults
/* split/join example */pipeline mypipe()
{gen_filter Generate();
split {
first_filter even();
second_filter odd();
} join;
av_filter Average();
}
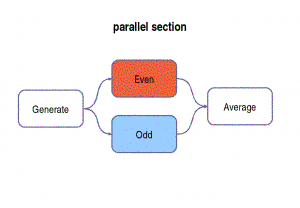
![]() When, like in this
example, the splitter / joiner are not specified, it is automatically instantiated
to a default roundrobin scheme. This roundrobin join (and associated split)
alternatively pops from every input queue (while the
splitter pushes to every output in sequence)
When, like in this
example, the splitter / joiner are not specified, it is automatically instantiated
to a default roundrobin scheme. This roundrobin join (and associated split)
alternatively pops from every input queue (while the
splitter pushes to every output in sequence)
Custom split / join
Additionally, splitter and joiner can be user defined (they are filters too) and you can specify what you want your splitter / joiner to do with code.
/* Example: how to use a user defined splitter and/or joiner */pipeline mypipe()
{gen_filter Generate();
split user_defined_splitter splitter(splitparams){
first_filter even();
second_filter odd();
} join user_defined_joiner joiner(joinparams);
av_filter Average();
}
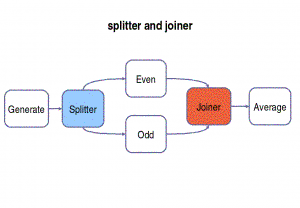
Feedback Loop
The language exports feedback loops to feed data back to earlier filters in a pipeline graph. This is the only way to build loops in a pipeline description, and it’s important that this happens in a structured fashion to preserve certain properties of the graph that are essential to the compiler ability to reduce and fold it during the code generation phases.
Additionally, and not to be underestimated, this prevent application level deadlocks due to the sole nature of the graph (while they can still happen because of the properties of the code associated to each filter).
/* Example: A simple (default) feedbackloop */pipeline mypipe()
{gen_filter Gen();
feedback {
Forward fwd();
Backward bwd();
} loop;
print_filter Sink();
}
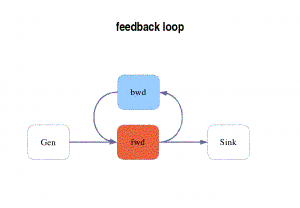
![]() In this example,
the filter fwd is not a joiner/splitter. A Joiner is implicitly added before,
and a Splitter after it.
In this example,
the filter fwd is not a joiner/splitter. A Joiner is implicitly added before,
and a Splitter after it.
Similarly to split/joins, you can define a custom joiner (and a splitter), to define the way data will be merged together from both inputs.
/* Example: A feedbackloop with custom joiner and splitter */pipeline mypipe()
{gen_filter Gen();
feedback myjoiner j(){
Forward fwd();
Backward bwd();
} loop mysplitter s();
print_filter Sink();
}
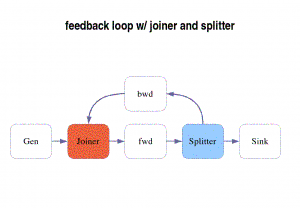
![]() When writing a
splitter or a joiner for a feedback loop, thus specifying queue indexes (c.f. Specify queue),
the queue 0 is always the exit. The queue 1 is thus the one fed back of the
loop.
When writing a
splitter or a joiner for a feedback loop, thus specifying queue indexes (c.f. Specify queue),
the queue 0 is always the exit. The queue 1 is thus the one fed back of the
loop.
![]() Very important !
When using the functional simulation nSTream (only available open source target
back-end for now), it is not possible to peek with an index
different than 0 when using a queue associated to a feedback loop. Thus, it is
important to avoid the use of either a peek(<n>)(n
> 0), or an input queue type bigger than 32bits ! For instance, on the
example before, the joiner could do whatever it wants on queue 0, but is
restricted to peek one element
at a time on queue 1 (coming from bwd). This is, of course, a bug!
Very important !
When using the functional simulation nSTream (only available open source target
back-end for now), it is not possible to peek with an index
different than 0 when using a queue associated to a feedback loop. Thus, it is
important to avoid the use of either a peek(<n>)(n
> 0), or an input queue type bigger than 32bits ! For instance, on the
example before, the joiner could do whatever it wants on queue 0, but is
restricted to peek one element
at a time on queue 1 (coming from bwd). This is, of course, a bug!
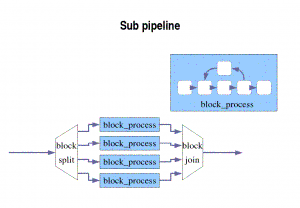
Sub-pipelines
In order to simplify the writing of applications in xSTreamC, you can instantiate a “pipeline” inside a pipeline description, instead of creating a pipeline section which would force you to replicate code.
pipeline mypipe()
{split block_split s(){
block_process b00();
block_process b01();
block_process b10();
block_process b11();
} join block_joiner j();
}
Filter Syntax
The filter is the basic construct of xSTreamC programs. Think of it as one task, although it’s not entirely correct, as the compiler might transform the code in ways that alter the number and content of such tasks automatically by merging them into larger ones (or in the future possibly splitting them), thus mapping a transformed pipeline from the one you described. The filter keyword is an attribute of functions. It can be used only before the declaration/definition of a “function”.
![]() Filters, like
pipelines, don’t have any return type.
Filters, like
pipelines, don’t have any return type.
filter myfunction(int param1, int param2)
A filter is not exactly a function:
A filter can have any number of input and output queues but basic filters are restricted to have a single input queue and a single output queue. Only special filters (split and join) use multiple input/output queues.
A filter defines a class or a prototype and once defined can be instantiated in any pipeline construct, multiple times.
A
filter can define parameters that are part of the filter state. The filter
instance parameters can be set during the filter instantiation or modified
during execution. See specific section on parameters
filter sections
A filter may only contain one or several specific sections. Each section represents a different phase and is a piece of C code, coding the behavior of the filter in the given phase. This code section can make use of xSTreamC extensions described in the next section.
The different sections are (so far):
- start: This code is executed only once at startup of the filter. If several streams (or better: frames) are sent into the pipeline, it won’t be re-executed.
- Parameter sensitive sections: cf actions taken upon reconfiguration
- init : This is the code executed every time a stream starts.
- work : This is the steady-state loop of the filter.
- eos : This describes the behavior of the filter when receiving a special “End Of Stream” frame in the data stream.
![]() Important : The
order in which sections are declared must be the one of the previous list
Important : The
order in which sections are declared must be the one of the previous list
There might be other sections in the futures, such as:
- more events guided sections, maybe eop (”End Of Pipeline”) ?
![]() Only the work
section is mandatory while the others can be omitted, if no specific behavior
is required.
Only the work
section is mandatory while the others can be omitted, if no specific behavior
is required.
example:
/* Filter sections */filter generate(int max)
{start {
<start code>}
init {
<init code>}
work {
<work code>}
/* No eos section => default behaviour */
}

filter parameters
declaring parameters
A
filter can have parameters, declared just like function parameters in C.
Initial value of a parameter
The value of a given parameter is set at the beginning of the filter initialization to the value specified at the corresponding instantiation in the pipeline description. In the example below, the filter generate has one parameter (max). The instance g of generate in the pipeline p will start with max=3.
/* Filter sections */filter generate(int max)
{...}
pipeline p()
{generate g(3);
...}
Subsequent changes of a parameter
![]() This is
runtime dependant. The following are only recommendations on how to implement the
parameter reconfiguration.
This is
runtime dependant. The following are only recommendations on how to implement the
parameter reconfiguration.
After the first instantiation of a pipeline, you can still modify the value of any parameter. Provided that the template (a back-end specific description file provided with the xSTream compiler for a given target: eg. Nstream) defines all the required structures to do it, the generated files should contain a description of the parameter hierarchy.
The template syntax example is a good one for generating such structures.
Thus, using custom macros, the runtime dependent headers provide macros/functions such as:
xst_gpe_configure_filter( handler,xst_get_config(my_pipeline, handler)->my_filter.my_param,
&new_value);
In the previous example, the call reconfigures, for the pipeline (of type my_pipeline) instantiated with handler handler, the parameter my_param of the filter my_filter to have a value new_value (that should have the same type as my_param).
![]() IMPORTANT NOTE:
Since the structures allowing you to use special constructs like
xst_get_config(my_pipeline, handler)→my_filter.my_param are generated, it means
that in such a case, the code for the gpe must be provided after the
generation.
IMPORTANT NOTE:
Since the structures allowing you to use special constructs like
xst_get_config(my_pipeline, handler)→my_filter.my_param are generated, it means
that in such a case, the code for the gpe must be provided after the
generation.
![]() The change of value for a parameter happens in
a way synchronous to the work section, that is until the work section is being
executed the old value is visible, after the work section has compled (e.g.
because and eos signal was received), then the new value is valid (a special
section can be defined to capture the change even as well).
The change of value for a parameter happens in
a way synchronous to the work section, that is until the work section is being
executed the old value is visible, after the work section has compled (e.g.
because and eos signal was received), then the new value is valid (a special
section can be defined to capture the change even as well).
![]() The code for
reconfiguring is supported for the GPE, so that it is done
in between stream processing (note that the notion of a stream is programmer
dependent, and can be as small as an array or as large of a whole image).
Your parameter will thus be changed in between different streams processing. (Encapsulated in the usual EOS signals for the protocol).
For instance, if your gpe code looks like:
The code for
reconfiguring is supported for the GPE, so that it is done
in between stream processing (note that the notion of a stream is programmer
dependent, and can be as small as an array or as large of a whole image).
Your parameter will thus be changed in between different streams processing. (Encapsulated in the usual EOS signals for the protocol).
For instance, if your gpe code looks like:
job1 = xst_gpe_call_pipeline_non_blocking(handler, stream_in1, size_in1, stream_out1, size_out1);
job2 = xst_gpe_call_pipeline_non_blocking(handler, stream_in2, size_in2, stream_out2, size_out2);
job3 = xst_gpe_call_pipeline_non_blocking(handler, stream_in3, size_in3, stream_out3, size_out3);
xst_gpe_configure_filter(handler, xst_get_config(my_pipeline, handler)->my_filter.my_param, &new_value);
job4 = xst_gpe_call_pipeline_non_blocking(handler, stream_in4, size_in4, stream_out4, size_out4);
...
The
parameter my_param will be actually changed between the end of the processing
of stream3 and the beginning of the processing of stream4 in the filter
my_filter.
Actions taken upon reconfiguration
Additionally, you can specify a code section that will be executed only when reconfiguring a given parameter. The syntax is the same as for other sections, using the parameter as section name:
filter my_filter(int my_param)
{my_param {
recompute_param_dependencies(my_param);
}
}
![]() Several important
remarks about this:
Several important
remarks about this:
- The section is executed only when reconfiguring, which means that it is not executed at startup of the filter. If you want this to happen, you should use the start section for the first execution.
- The section is executed after the change of the parameter. So that you can safely assume that your parameter has the new value when executing it.
- As mentioned before, the
reconfiguration mechanism is done in between stream processing.
For this very reason, it has no meaning to use communication primitives
inside a parameter section. It would lead to an immediate
deadlock/exception.
streaming code
We'll now describe the extensions to the low level C, starting with how to manage the input / output queues of each filter. There are four primitives to do so : push / pop / peek / drop / try
Don’t
forget to read the common consideration section
below.
push
A push is used to send data on the output queue. In order to keep them simple and easy to isolate, the only way to use it is
/* Push syntax */push(<expression>);
This means that you cannot use them inside group expressions or compound statements
Here is the example of a generator :
/* A simple generator */filter generate(int max)
{work {
int i;
for(i=0; i < max; i++)
{
push(i);
}
/* make it even */
if(max % 2)
push(0);
}
}pop
The pop reads and dequeues the first data of the input FIFO. Its syntax is even more restrictive, since it has to be an assignment to a variable.
/* Pop syntax */variable <ASSIGN_OP> pop();
/* <ASSIGN_OP> can be any of =, -=, +=, *=, /=. */
Here is the example of a simple filter that computes the average of pairs of numbers.
/* Simple average function */filter average(){work {
int a;
a = pop();
a += pop();
push(a/2);
}
}
peek
The peek reads an element of the input queue (not necessarily the first one) without dequeuing it. It takes as an argument the index of the element to peek. It has the same restrictions as the pop.
/* Peek syntax */variable <ASSIGN_OP> peek(<num>);
/* <ASSIGN_OP> can be any of =, -=, +=, *=, /=. *//* <num> is the index in the input queue */
drop
The drop consumes elements of the input queue. It takes as argument the number of elements to be consumed. It must be declared alone in a statement, since you can consider it as a function returning void.
/* Drop syntax */drop(<num>);
Here is the same example given previously for pop, but using peek and drop...
/* The average example rewritten with peek and drop */filter average(){work {
int a;
a = peek(0);
a += peek(1);
push(a/2);
drop(2); /* This is exactly equivalent to pop(); pop(); */
}
}
try
The try returns whether there are (or there will be) enough elements in a given queue. It will never set an EOS flag. Otherwise, it would behave just like a peek, only returning the EOS flag instead of the value.
/* Try syntax */<condition-keyword>(try(<num>))...
/* Try can be used with if, while, or in the middle statement of for (the condition one)
Here is an example of try : a minimum joiner (computing the minimum value out of N queues):
filter join_min(){work {
int present = 0;
int min;
int data;
int q;
for(q=0;q < @NB_QUEUES_IN@; q++) // See template_syntax for NB_QUEUES_IN explanation
{
if(try(0,q))
{
data = pop(q);
if(!(present++)
|| data < min)
min = data;}
}
if(present == 0)
peek(0,0); // Trigger one of the EOS (one on every queue here)
else
push(min);
}
}
Presently, filter fusion for filters with peek or drop are possible only when the index of the peek/drop is static (a compile time constant).
![]() Important: These
four operations are blocking. That is, if you try to pop an empty input queue, push on a full output queue,
or peek more than the
number of elements in an input queue, the filter will stall until the blocking
condition is lifted.
Important: These
four operations are blocking. That is, if you try to pop an empty input queue, push on a full output queue,
or peek more than the
number of elements in an input queue, the filter will stall until the blocking
condition is lifted.
Try vs. Peek
|
Case |
Signal Seen <
N |
Behavior Peek |
Behavior Try |
Comment |
|
Value reached |
NO |
Return value |
Return 1 |
Easy case where data available... |
|
Blocking |
NO |
Wait for data / Signal |
|
|
|
Signal reached |
YES |
Set Signal Flag * and return 0 |
Return 0 |
Data available, but signal crossed |
*
Signal register is updated with value of first signal encountered, signal
status informs if peek matches a
signal or if peek element is
beyond a signal.
common considerations
Data type
In xSTreamC, you can pass data of any type. Not only types allowed for function parameters, but also more complex data like user-defined struct / union / typedef / arrays. Thus, of course, the size of the data to peek / pop / push / drop / try is not restricted.
![]() Each filter has one
input type and one output type (at least for now), that are
automatically inferred from the usage of primitives in the code, the compiler
flags as errors inconsistencies for different inferred types, that is the data
types associated to queues are strongly typed.
Each filter has one
input type and one output type (at least for now), that are
automatically inferred from the usage of primitives in the code, the compiler
flags as errors inconsistencies for different inferred types, that is the data
types associated to queues are strongly typed.
For example, the following code will NOT compile.
filter a(){work {
int b;
float c;
b = pop();
c = pop();
}
}
Plus, two filters linked to each other must have the same type for the FIFO they define. That is, the output type of the first filter has to be the same as the input type of the second one.
The language supports the generic type to allow generic filters consuming and producing data with types that are automatically inferred at instantiation time.
Localization (Peek/Push/Pop in subfunctions)
Until version 0.5 of xSTreamC compiler, it was not possible to use these communication primitives outside of a filter. This extension was later on supported so that one could use any of the communication primitives at any time in the code, provided the following conditions are met:
- If a function contains a communication primitive, it can be called ONLY from a filter eventually. Possibly, several layers of functions could be nested in between, but none of the functions calling a Peek/Push/Pop or a function leading to a Peek/Push/Pop call will be allowed in the main function.
- The type of the queue used for the communication primitive in a function should be the same as any other primitive called in the master filter for the same kind of primitive (input/output).
- A function called in a filter and containing primitives will have to be localized, that is made private to the filter. If several filters call the same function, or if there are several instances of a filter, each one of them will use a different function (in a way similar to C++ templates). In particular, using static variables would keep a state in the function which is private to the filter that is valid only across calls from the same instance. On the next example, filter f uses such a function, but two instances of f (f0 & f1) will be created, having each one a private version of wrapped_int_pop. Two counters “count” will be kept.
int wrapped_int_pop()
{static int count=0;
int a;
a = pop();
count++;}filter id(){work {
int a;
a = wrapped_int_pop();
push(a);
}
}pipeline p()
{f f0();
f f1();
}
- If a filter contains any
localized function, it will not be possible for the compiler to merge it
with any other filter. You should use this language feature sparingly and
only to the larger filters functions.
Special 'generic' type
Since filters can be reused in several places, it would be a very restrictive constraint to have a fixed data type for the FIFO, as instantiating it several times in different circumstances could force one to replicate a filter code multiple times for different queue types. For example, a simple swap filter could be used between two ‘int’ filters, as well as between two ‘float’ filters.
/* Use of generic type */filter swap(){work {
generic a, b;
a = pop();
b = pop();
push(b);
push(a);
}
}pipeline swap_int()
{generate_int g();
swap s();
consume_int c();
}pipeline swap_float()
{generate_float g();
swap s();
consume_float c();
}
Specify queues
peek / push / pop / drop / try have an optional argument (the last one) which specifies the queue on which the operation should be done. A standard filter cannot have more than one in and out, so it is not useful there. This extension of the syntax is to be used mostly to program splitters and joiners.
![]() Result of using
non mapped queues is not defined.
Result of using
non mapped queues is not defined.
Advanced automation using xSTreamC
![]() This is not a part
of the language, but supported by the compiler.
This is not a part
of the language, but supported by the compiler.
The xSTreamC compiler supports a whole syntax set to be able to define the format of its output code (c.f. template syntax). This syntax is intended only for the output code. However, it is still understood in whatever filters code, and could also be used as an advanced feature.
For example, you can use this feature to write a generic splitter, by using the place_holder @NB_QUEUES_IN@. You can see examples of that in the xStreamC compiler high level library