To generate low level code starting from the xSTreamC code for a specfic streaming fabric definition, the compiler applies a set of target dependent templates. These template will capture the dependencies from the specific simulation environment (if simulating an architecture), or the actual run-time support for a real platform. The template also captures the whole notion of a filter control flow, and how different filter sections are activated (e.g. by way of receiving in-bound signaling data for events such as end of a frame or parameter change events). This page describes the language used to write these templates. In General for every target there should be a template although the compiler will emit some code even if one is not provided. You can then use a different template for compiling your xSTreamC code, by provinding its name to the compiler with an option (-f).
In order to write a new template definition file one should be familiar with the xSTreamC compiler internals and the protocols used to encapsulated events in the data flow, although it's theoretically possible to use these same extensions in a user level applications (e.g. within a filter), this is not reccomended.
A template file has two mandatory functions : filter_tmpl and pipeline_tmpl. These are just identifier names, not reserved keywords.
Within these functions definition, a special syntax is used to specify magic place holders, associated to iterative filter sections, and to allow the compiler to generate types and initializers, as well as expanding the rest of the code of the template in proper places in the high level language constructs of the input files
This function is the filter body template, used to drive the lowering of the user level filter code
It has two requirements :
Here is a very simple example.
int filter_tmpl(int myparam) { @PEEK@(mypeekfunction(@QUEUE_IN@, @PEEK_INDEX@));
@POP@ (mypopfunction (@QUEUE_IN@));
@PUSH@(mypushfunction(@QUEUE_OUT@, @PUSH_DATA@));
@DROP@(mydropfunction(@QUEUE_IN@, @DROP_INDEX@));
printf("The filter %s is before initialization\n", @FILTER_NAME@);
@SECTIONS@(!_xst_received_eos(@DEFAULT_QUEUE_IN@)) printf("The filter %s is exiting\n", @FILTER_NAME@);
}
This template describes the function invoking a pipeline. It is based on a pipeline_description structure containing all the filters, their mapping, and the connections between them. It has no mandatory fields for the compiler. However, the runtime API requires that a pipe description struct is given. (see type iteration)
Place holders can be used anywhere in the code of a template function. For example, see in the previous example the @FILTER_NAME@ place holder...
For more details, see place holders reference
An important aspect is associated to levels in the template syntax. There are five possible 'levels' and is possible to go from one level only onto the next. For example, you can go from PIPE_LEVEL to FILTER_LEVEL. On the left of the image below, you can see the starting point for both templates, which is quite intuitive.
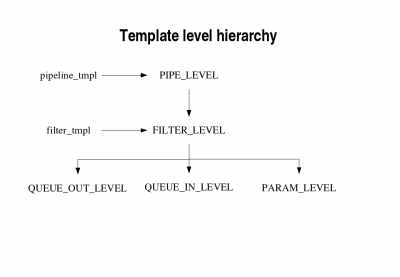
These levels can be used to replicate a section of code on the given level. This allows to iterate operations on all filters / params / queues.
Most place holders meaning depends on the level at which they're used. For example, using @FILTER_NAME@ at PIPE_LEVEL will generate an error! But you can use it at PARAM_LEVEL, since it is inside the FILTER_LEVEL...
There are two syntaxes to duplicate sections.
/* This syntax is only for statements */ <LEVEL_SPECIFIER>{ <some code> }
/* This syntax can be used everywhere */ <LEVEL_SPECIFIER>(<some code>);
As a dummy example, you can have the list of filters...
pipeline_tmpl { /* We are at PIPE_LEVEL */ printf("In this pipeline, there are the following filters:\n");
@FILTER_LEVEL@ { printf(" %s\n", @FILTER_NAME@);
} }
As a very special case, for the second of the syntaxes, you can specify directly a binary operator, with one operand being @DUMMY@. This will have as an effect to iterate the binary operation directly, not the piece of code. The @DUMMY@ is where the next one is to be placed...
This code gives the total number of input queues of the filters:
pipeline_tmpl() { int nb_queues;
nb_queues = @FILTER_LEVEL@( @DUMMY@ + @NB_QUEUES_IN@);
/*
* For three filters having respectively 3 1 2 queues, this would be extended as:
* nb_queues = (( 2 + 1 ) + 3);
*
* specifying @FILTER_LEVEL@( @NB_QUEUES_IN@ + @DUMMY@) would have been extended as:
* nb_queues = (3 + (1 + 2))
*/ }
A template also needs to have the ability to create new types, and initialize the variables declared with those types. This is done with a mix of level markers and place holders. Both processes (type and initializer creations) are quite dependent, so you cannot use one without the other.
Basically, the process boils down to fill some structures with data, that is taken care of by the initializer part. Additionally, one often wants a structure to represent a pipeline, filter, queues or paremeters. That is why you also have the opportunity to create types
To start this process, put a type between @@, in a declaration of one of your template functions: The type refered to will be the base for the replication.
typedef struct mytype_ { (...) } mytype_;
int pipeline_tmpl() { @mytype_@ a; }
This first dummy example would generate a type with the name being the concatenation of this and the pipeline name, for every pipeline (because this example is in pipeline_tmpl, thus starting at PIPE_LEVEL). For example, if two pipelines pipe0 and pipe1 are declared in this example, it would generate:
typedef struct mytype_pipe0 { (...) } mytype_pipe0;
typedef struct mytype_pipe1 { (...) } mytype_pipe1;
In a more complex example, you could iterate on the all the filters in a pipeline.
typedef struct myfiltertype_s { char *name;
int input_queues;
int output_queues;
} myfiltertype_t = @FILTER_LEVEL@;
typedef struct mytype_ { myfiltertype_t a_dummy_name; } mytype_;
int pipeline_tmpl() { @mytype_@ a; }
This example describes a structure having one element of type myfiltertype_t. This element is marked (through a =@FILTER_LEVEL@ after the type declaration) as a FILTER_LEVEL element, which will automatically create a duplication of itself into as many elements as the filters in this pipeline.
![]() The name used for this element (a_dummy_name) is irrelevant here, as
it will be replaced by the filter name in the generated type.
The name used for this element (a_dummy_name) is irrelevant here, as
it will be replaced by the filter name in the generated type.
If you use this template on the following code:
(...) pipeline myexamplepipe(){ FIR_filter fir0();
split duplicate dup(){ FIR_filter fir1();
FIR_filter fir2();
FIR_filter fir3();
id i();
} join; /* Default here => roundrobin */ } pipeline anotherpipe(){ filter0 f();
filter1 g();
}
... xSTreamC will generate the following type:
/* This type is left unchanged ! */ typedef struct myfiltertype_s { char *name;
int input_queues;
int output_queues;
} myfiltertype_t;
typedef struct mytype_myexamplepipe { myfiltertype_t fir0; myfiltertype_t dup; myfiltertype_t fir1; myfiltertype_t fir2; myfiltertype_t fir3; myfiltertype_t i; myfiltertype_t _tmp0; /* An automatic name for the default roundrobin joiner */ } mytype_myexamplepipe;
typedef struct mytype_anotherpipe { myfiltertype_t f; myfiltertype_t g; } mytype_anotherpipe;
One can notice that the fields of the struct in the previous example have been left blank. This was to avoid confusion. Most of the time, you will want to initialize the content of these structures in a certain way with place holders.
xSTreamC will automatically go through structures having a '= @INITIALIZER@' and fill them...
An easy example: your template for pipelines is:
typedef struct pipeline_s { int nb_filters = @NB_FILTERS@;
} pipeline_t;
return_t pipeline_tmpl(parameter_t p) { pipeline_t mypipeline = @INITIALIZER@; pipeline_t tmp_pipeline; }
This would generate (for pipe0 and pipe1 being two pipelines having resp. 4 and 7 filters).
/* Type unchanged (no a templated type !) */ typedef struct pipeline_s { int nb_filters;
} pipeline_t;
/* The pipeline functions: */ return_t pipe0(parameter_t) { pipeline_t mypipeline = {4};
pipeline_t tmp_pipeline; /* Not initialized, because not asked to */ } return_t pipe1(parameter_t) { pipeline_t mypipeline = {7};
pipeline_t tmp_pipeline;
}
It is allowed to go through as many types as desired:
typedef struct mytype_ { int nb_filters = @NB_FILTERS@;
@other_type_@ ot; /* This will be expanded in the exact same way */ well_defined_type wdt; /* This one will only be expanded for the initializer */ } mytype_;
As for standard template code, you can change level (across types), by specifying the level marker as an �€˜initializer�€™ to the typedef declaration:
typedef struct parameter_s { int size = @PARAM_SIZE@;
} parameter_t = @PARAM_LEVEL@;
typedef struct s_filter_ { int nb_params = @NB_PARAMETERS@;
parameter_t dummy_param_name;
} filter_ = @FILTER_LEVEL@;
typedef struct s_pipe_ { int nb_filters = @NB_FILTERS@;
@filter_@ dummy_filter_name;
} pipe_;
int pipeline_tmpl() { @pipe_@ pipe_descriptor; (...)
}
Look at the result for the following pipeline.
filter a(int a0, double a1);
filter b(char b0);
pipeline mypipe() { a aa0();
a aa1();
b bb0();
}
Here is the generated code...
/* types */ typedef struct parameter_s { /* Already well defined type, kept as is */ int size;
} parameter_t;
typedef struct s_filter_a { /* filter_t for filter a */ int nb_params;
parameter_t a0;
parameter_t a1;
} filter_a;
typedef struct s_filter_b { /* filter_t for filter b */ int nb_params;
parameter_t b0;
} filter_b;
typedef struct s_pipe_mypipe { /* pipe_ for pipeline mypipe */ int nb_filters;
filter_a aa0;
filter_a aa1;
filter_b bb0;
} pipe_mypipe;
/* initializer */ int mypipe() { pipe_mypipe pipe_descriptor = { 3,
/* Initializer for filter aa0 (of type a) */ { 2, /* number of parameters in a */ {4}, /* parameter a0 of a */ {8} /* parameter a1 of a */ },
{ 2, {4}, {8}},
{ 1, {1}},
};
(...) }
All these types and initializers can then be used in your GPEcode, to set parameters, or make references to filters. For example, getting the size of parameter a1 of the instantiation aa0 of filter a is a very simple process of getting struct fields:
pipe_mypipe pipeline_descriptor ...;
size_of_aa0_a1 = pipeline_descriptor->aa0.a1.size;
The structure containing the whole pipeline description should also be specified in the template file. The first part of the pipeline_tmpl will iterate on this struture to instantiate filters, send code, and set up whatever is necessary... The filling of this structure is done through some meaningful markers included in the declaration of the pipeline_description_type.
For example, see this extract of an actual template
typedef struct xst_pipeline_description_element_s
{ /** Name of the filter */ const char *filter_name = @FILTER_NAME@;
/** Physical node assigned to this filter */ unsigned int physical_node_assigned = @PHYSICAL_NODE@;
} xst_pipeline_description_element = @FILTER_LEVEL@;
typedef struct xst_pipeline_description_s
{ /** Number of filters in this pipeline */ unsigned int number_of_filters = @NB_FILTERS@;
/** Pipeline description elements */ xst_pipeline_description_element *pipeline_elements; } xst_pipeline_description;
Putting a marker on a field will give meaning to it, provided that it is a marker known by xSTreamC. Putting a marker on a typedef (like @FILTER_LEVEL@ in the example), will set the level of iteration of this structure. Thus, calling an element of this type will automatically iterate the structure on it. In this case, an array with one element for each filter will be created.
Here is the table with all place holders, and the valid levels for them.
| LEVELS | ||||||
|---|---|---|---|---|---|---|
| PIPE_LEVEL | FILTER_LEVEL | PARAM_LEVEL | QUEUE_IN_LEVEL | QUEUE_OUT_LEVEL | Description | |
| NB_FILTERS | X | Number of filters inside the current pipeline | ||||
| START_POINT | X | Filter index of the first filter in current pipeline | ||||
| PIPE_NAME | X | Name of the current pipeline (no quotas) | ||||
| PIPE_STR | X | String with name of the current pipeline (with quotas) | ||||
| NB_QUEUES_IN | X | X | X | X | Number of input queues of current filter | |
| NB_QUEUES_OUT | X | X | X | X | Number of output queues of current filter | |
| DEFAULT_QUEUE_IN | X | X | X | X | Index of default input queue (the one chosen when no index is given to a push / pop / peek / drop of the current filter | |
| DEFAULT_QUEUE_OUT | X | X | X | X | Index of default output queue (the one chosen when no index is given to a push / pop / peek / drop of the current filter | |
| PHYSICAL_NODE | X | X | X | X | Number of the physical node (XPE) on which the current filter is mapped | |
| FILTER_NAME | X | X | X | X | Name of the current filter (no �€œ�€œ) | |
| FILTER_STR | X | X | X | X | String with name of the current filter (with �€œ�€œ) | |
| FILTER_NUMBER | X | X | X | X | A pipeline wide unique number for the current filter | |
| FILTER_FUNCTION | X | X | X | X | Pointer to the function representing the current filter | |
| START | X | The start section | ||||
| PARAM_SIZE | X | Size (in bytes, like sizeof) of the current parameter | ||||
| PARAM_INDEX | X | The index of the current parameter (for �€œfilter a(int a0, float a1)�€, a0 has index 0) | ||||
| PARAM_ID | X | The variable representing the current parameter (to be used in code) | ||||
| PARAM_NAME | X | The name of the current parameter (as declared in input file, no �€œ�€œ) | ||||
| PARAM_STR | X | A string containing the name of the current parameter | ||||
| PARAM_TYPE | X | Type of the current parameter (for a cast...) | ||||
| PARAM_VALUE | X | The value of the current parameter (value set when instantiating the filter in the pipeline description) | ||||
| PARAM_SECTION | X | The complete section associated to the current parameter. | ||||
| QUEUE_IN | X | The current input queue index | ||||
| QUEUE_INITIATOR_NODE | X | The PHYSICAL_NODE of the initiator node (for the given queue) | ||||
| QUEUE_OUT | X | The index of this queue on the initiator node | ||||
| IS_IN_LOOP | X | Whether data in this queue can depend from itself | ||||
| PEEK_INDEX | X | The queue index for a peek (peek prototype) | ||||
| DROP_INDEX | X | The queue index for a drop (drop prototype) | ||||
| TRY_INDEX | X | The queue index for a try (try prototype) | ||||
| QUEUE_OUT | X | The current output queue index | ||||
| QUEUE_TARGET_NODE | X | The PHYSICAL_NODE of the target node | ||||
| QUEUE_IN | X | The index of this queue on the target node | ||||
| PUSH_DATA | X | The data to be pushed (push prototype) | ||||
| IS_BACKWARD_QUEUE | X | Whether this queue is the splitter feedback output queue going backward | ||||